
Die Erkennung von Anomalien ist eine wichtige Maßnahme in der IT-Security. Um diese richtig umsetzen zu können, gibt es verschiedene Ansätze und Lösungen.
Was sind Anomalien?
Per Definition sind Anomalien unerwartete Abweichungen oder Unregelmäßigkeiten zu einem Normal- oder Normzustand. Dieser Normzustand wird häufig nach einer Einschwingphase definiert.
Um die Abweichungen vom Normalen zu erkennen, setzt man in der IT in der Regel auf Systeme zur Anomalieerkennung. Diese helfen dabei, ungewöhnliche Muster zu erkennen.
Beispiele für Anomalien in IT-Systemen
Unbekannte oder auffällige Abweichungen können sein:
-
- Erhöhtes oder anderes Datenaufkommen in einem Netzwerk oder auf einer Website
- Unbekannte oder veränderte Datenpakete
- Neue, nicht im Normzustand vorhandene Netzwerkverbindungen
- Neue Geräte oder User-Accounts in einem Netzwerk
- Datenverkehr über ungewöhnliche Protokolle
- Nicht genehmigte Scans von Systemen
- Seltsame oder unbekannte Fehlermeldungen
- Unbefugte Installation von Applikationen
- Änderungen von Konfigurationseinstellungen
- Deaktivierung von Security-Funktionen
Sie sehen: Viele Auffälligkeiten fallen in den Bereich Netzwerk-Anomalie. Doch es gibt zudem zahlreiche “mysteriöse” Veränderungen auf Systemebene – zum Beispiel bei Einzelplatz-Computern. Deshalb ist es wichtig, das Thema “Anomalieerkennung” holistisch zu betrachten.
Wie funktioniert Anomalieerkennung?
Agieren Sie niemals nur nach einem Bauchgefühl!
Um Abweichungen von einem Normzustand erkennen zu können, muss man zuerst den Normzustand definieren. Legen Sie dafür Kennzahlen fest, die eindeutig über einen langen Zeitraum messbar sind. Zudem sollten Sie Schwellenwerte definieren, ab wann der Normbereich verlassen wird und man von einer Anomalie sprechen kann.
In der IT ist es üblich, die Anomalieerkennung über verschiedene Methoden und Systeme zu automatisieren. Es werden hierbei unter anderem regelmäßig Messungen durchgeführt und Log-Dateien ausgewertet.
Im besten Fall werden diese Log-Daten im Rahmen einer Security-Strategie zentral in einem Log-Management-System gesammelt und (korreliert) ausgewertet.
Sie haben Fragen zum Thema? Kontaktieren Sie uns!
Warum ist Anomalieerkennung so wichtig?
Alles, was von einer Norm abweicht, kann gefährlich sein. Im Medizinbereich könnte eine Auffälligkeit auf eine schwere Krankheit hindeuten, im IT-Bereich sind eventuell Cyber-Angriffe der Grund für Unregelmäßigkeiten.
Mit einer professionellen Anomalieerkennung (englisch: Anomaly Detection) können Sie beispielsweise Schwachstellen in Ihrem Netzwerk oder erfolgreiche Hacker-Angriffe feststellen. Wenn sinnbildlich die Alarmglocken erklingen, sollten Sie schnellstmöglich Gegenmaßnahmen einläuten!
Haben Sie keine Prozesse oder Systeme zur Anomalie-Erkennung im Einsatz, sind Sie quasi blind: Sie bekommen gar nicht mit, wenn “Cybergangster” in Ihre IT-Infrastruktur oder IT-Systeme einbrechen, Ihr Unternehmen ausspionieren oder Daten stehlen.
Diese Blindheit kann mehrfach teuer werden: Es fließen vielleicht geheime Informationen ab und es kommt zu einem Image-Verlust bei Bekanntwerden des Data Breaches.
Dazu können unter Umständen saftige Strafzahlungen folgen, weil Sie Ihre Infrastruktur nicht richtig abgesichert haben. Eine professionelle Absicherung wird aber mittlerweile in vielen Bereichen gesetzlich gefordert!
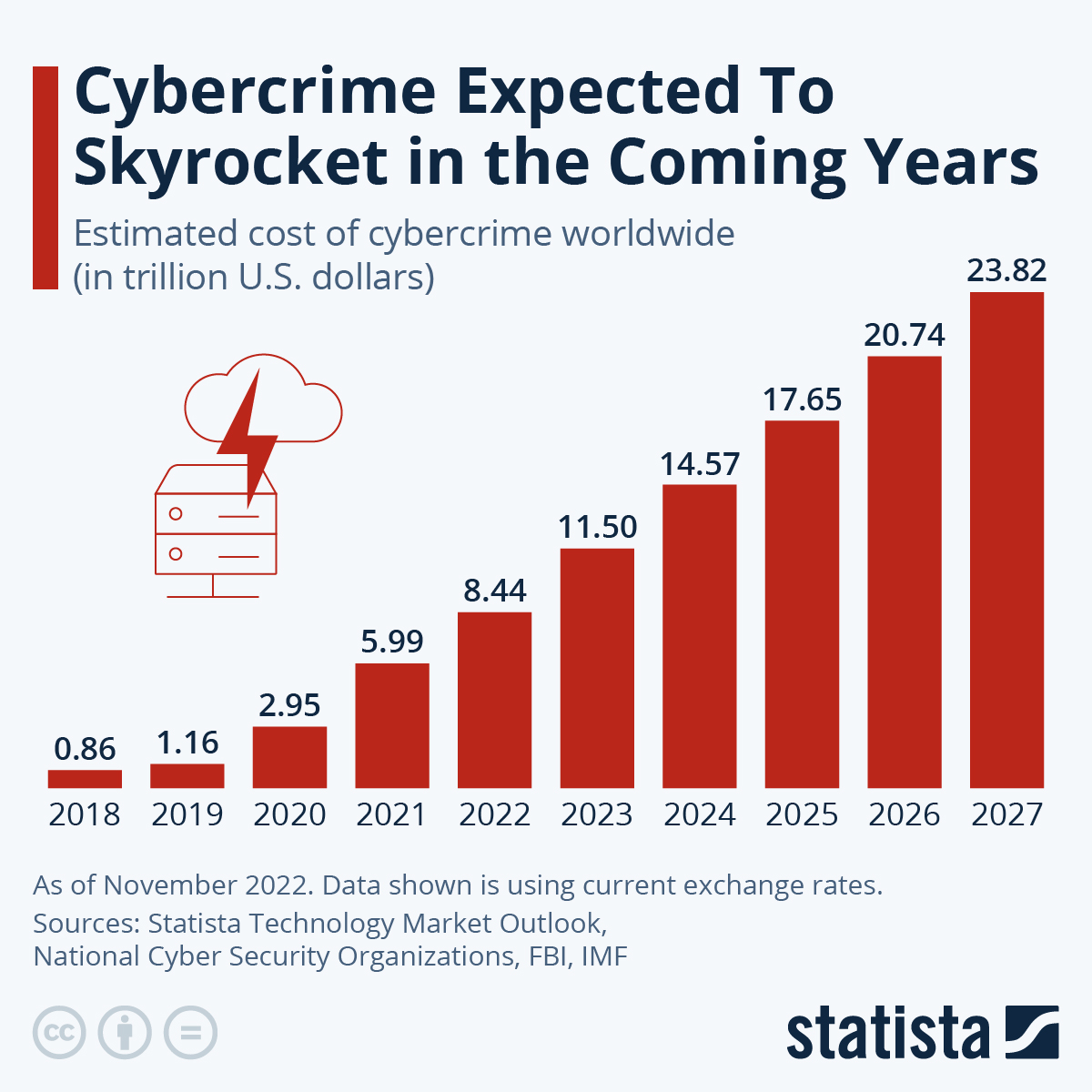
Gibt es Gesetze und Normen, die Anomalieerkennung vorschreiben?
Ja. So fordert das IT-SiG 2.0 bzw. das BSI-Gesetz, dass besonders Firmen im Bereich KRITIS (Kritische Infrastruktur) spezielle Systeme zur Angriffserkennung einsetzen müssen. Verpflichtende Funktionen dieser Systeme sind unter anderem die Erkennung und Protokollierung von Anomalien.
Zudem setzt sich die ISO 27001 als Zertifizierungsstandard in vielen Branchen und Industrien durch. In diesem Rahmen müssen Sie ein ISMS (Informationssicherheitsmanagementsystem) etablieren. Darin muss zum Beispiel eine Anomaliedetektion enthalten sein.
Weitere Regularien und Vorschriften wie VDA-ISA TISAX oder DORA fordern IT-Security-Maßnahmen und -Systeme auf dem aktuellen Stand der Technik. Und das BSI hat im Juni 2023 die Version 2.0 seines “Mindeststandard zur Protokollierung und Detektion von Cyber-Angriffen” veröffentlicht.
Welche Systeme zur Anomalieerkennung gibt es?
Da es nicht _die_ Anomalie gibt, gibt es dementsprechend nicht _das_ Anomalie-Erkennungssystem. In den letzten Jahren haben sich im Bereich der Informationssicherheit verschiedene Konzepte und Lösungen etabliert. Beispielsweise diese:
-
- IDS: Intrusion Detection Systems
- SIEM: Security Information & Event Management
- SEDM: Security Event Detection Management
- MDR: Managed Detection & Response
- XDR: Extended Detection & Response
Hardening-Audits kann man ebenso in den Bereich der Anomalieerkennung zählen.
Was muss man bei der Anomalieerkennung beachten?
Log-Analysen ohne sinnvolle Strategie führen häufig zu Security-Teams, die in einer Flut an (Falsch-) Meldungen untergehen. Oft sind “False Positives”, also Fehlalarme, die Ursache dafür.
Deshalb ist es wichtig, einerseits dafür zu sorgen, dass es zu möglichst wenig “Events” kommt. Andererseits ist es wichtig, aus der Flut an (Falsch-)Meldungen die wirklich relevanten herauszufiltern. Gerade für SOC-Analysten ist die Risikobewertung eines Alarms wichtig.
Die Risikobewertung kann nur im Kontext geschehen – wenn also der Alarm in den Zusammenhang mit der Infrastruktur gesetzt wird. Diesen Kontext manuell zu ermitteln ist aufwendig, zeitraubend und bedarf ein hohes Maß an Wissen über die Infrastruktur. Das sind alles Dinge, die im Fall der Fälle nicht zur Verfügung stehen
Beispiel: Ein erkannter Angriff, der das bereits als “knackbar” angesehene Protokoll SMBv1 aktiv ausnutzt, ist natürlich nur für solche Systeme relevant, die SMBv1 noch aktiviert haben. Der Kontext, in dem der erkannte Angriff oder die Anomalie stattfindet, spielt somit eine entscheidende Rolle.
Dieses Video zeigt Ihnen, wie ein Angriff über die SMBv1-Lücke abläuft und wie eine Härtung dagegen hilft:
Wie gehören Anomalieerkennung und Systemhärtung zusammen?
Die sichere Konfiguration von Applikationen und Betriebssystemen, das sog. “Härten” bzw. “Hardening”, sorgt dafür, dass es weniger Angriffsflächen gibt. Denn – vereinfacht gesagt – wo es keine Schwachstelle gibt, kann es folglich keinen Missbrauch geben.
Dementsprechend sorgt eine Systemhärtung auch dafür, dass weniger Anomalien und False Positives gemeldet werden. Das SOC-Team wird auf diese Weise massiv entlastet.
Damit Sie Ihre Systeme effektiv härten können, müssen Sie regelmäßig Audits durchführen. Damit lassen sich Schwachstellen und Optimierungspotenziale erkennen.
Einen solchen Check können Sie bequem mit dem AuditTAP durchführen. Das AuditTAP erkennt ungewöhnliche Einstellungen und weist sie darauf hin.

Möchten Sie dauerhaft und automatisiert Ihre gehärteten Systeme überprüfen? Dann sollten Sie den Enforce Administrator einsetzen. Das Hardening-Tool für Unternehmen bietet zahlreiche Funktionen. Eine ist die Anomalie-Erkennung auf Konfigurationsebene.
Das heißt: Wird in Ihrer Systemlandschaft eine Konfiguration verändert – aus Versehen oder durch Cyber-Angriffe – erkennt der Enforce Administrator diese Anomalie und macht sie eigenständig wieder rückgängig. Die entsprechende Eskalationsstufen kann starten. Derart entsteht eine Art “selbstheilendes System” mit vollständiger Kontrolle über die Laufzeit und den Lebenszyklus von IT-Systemen.
Wird Anomalieerkennung durch Machine Learning besser?
Algorithmen, die auf Machine Learning (ML) oder anderen Formen von Künstlicher Intelligenz (KI) basieren, können ein System zur Anomalieerkennung besser machen. Sie sorgen dafür, dass Veränderungen schneller erkannt und zugeordnet werden. Die Anzahl an Fehlalarmen nimmt – teilweise signifikant – ab.
Das bedeutet, Machine Learning ist eine sinnvolle Erweiterung zu der regelbasierten Erkennung. Das Ergebnis: Aus einem hohen Datenvolumen mit geringem Informationswert wird ein möglichst geringes Datenvolumen mit hohem Informationswert.
An dieser Stelle ein kurzer Hinweis auf unseren Partner Trovent Security GmbH: Die dort entwickelte Context Engine hilft Security-Teams/SOCs/CSIRTS, Ereignisse in einen Kontext zu setzen und so die Bearbeitungszeit deutlich zu beschleunigen.
Fazit: Benötigen Unternehmen ein Anomalie-Erkennungssystem?
Ja, definitiv! Um IT-Systeme umfassend schützen zu können, benötigt es den Dreiklang aus “Protection”, “Detection” und “Reaction”. Methoden und Systeme zur Anomalieerkennung fallen in den Bereich “Detection”, die Systemhärtung in den der “Protection”.
Beide sind eng miteinander verzahnt. Denn etwas, das gut konfiguriert und damit geschützt ist, erzeugt deutlicher weniger Anomalien.
……….
Wollen Sie mehr über Systemhärtung erfahren und praktische Tipps zur sicheren Konfiguration von Systemen erhalten? Folgen Sie uns auf LinkedIn! Oder möchten Sie wissen, wie Sie eine (automatisierte) Systemhärtung professionell realisieren und in Ihrem Unternehmen implementieren können? Sprechen Sie uns an – unsere Experten sind gerne für Sie da!
Bild: Adobe Firefly